不实际试穿,就能尝试各种服饰,虚拟试衣技术让「QQ秀」升级成了真人版,为时尚行业打开了新世界的大门。
然而,现有的虚拟试衣方法在逼真性和细节上的一致性方面还存在挑战。虽然扩散模型在创造高品质和真实感图像方面表现出众,但在虚拟试衣等特定场景中,它们在维持控制力和一致性方面还有待提高。
Outfit Anyone 利用了一种创新的双流条件扩散模型,有效地解决了这些问题,能够精确地处理服装的变形效果,实现更加逼真的试穿体验。Outfit Anyone最大的特点是其极强的适应性和广泛的应用范围,不仅能调整以适应不同的姿势和体形,无论是动画形象还是真人,都可以一键换装。现已开放试玩。

GitHub: https://github.com/HumanAIGC/OutfitAnyone
Project: https://humanaigc.github.io/outfit-anyone/
Demo 体验 (V0.9):
Modelscope: https://modelscope.cn/studios/DAMOXR/OutfitAnyone/summary
Huggingface Demo: https://humanaigc.github.io/outfit-anyone/
主要方法:条件扩散网络
虚拟试衣任务本质是一个条件生成的任务,也就是基于给定一张服饰图片作为条件输入,控制生成服饰在人身上的试衣图片。当前的 diffusion model 在生成的可控性方面做了很多工作,比如基于 tuning-based 的方法,如 lora, dreambooth 等,可以实现通过针对某一个或几个概念的样本图片进行针对性训练,学习对应的某个 concept, 在生成的过程中可以实现对应 concept 或者物体的生成。然而这种方式以来 finetuning,计算和时间成本高,且难以扩展到多个物体的同时生成。
另外一类控制生成的方法是以 controlnet 为代表,其主要原理是通过 zero-conv 训练一个插件的网络,可以实现利用 mask,canny edge, depth 等多种信号控制最终生成图片的 layout。这种方式的最大的弊端在于控制信号与目标图像在空间上是 align 的,但服饰与控制信号和目标图像在空间分布上有较大的差异,导致无法直接使用,从而限制了其应用的拓展范围。
因此,作者提出了一种新的支持试衣功能的条件生成网络,实现服饰的形变,光照的变化,服饰新视角变化情况下的生成,同时能够保持服饰的纹理,版型,细节的一致性。
相比 lora,dreambooth 等方法的好处是,不再需要针对每个物体进行 finetuning,具有很强的泛化性,从而可以实现 zero-shot 一键试衣。
此外,为了提升试衣结果的真实性,作者提出了 refiner 网络,对服饰的细节进行提升,从而能够提升服饰的材质、色彩,使其更接近真实的试衣效果。Outfit Anyone也支持各种复杂的服饰,多样的姿势,以及适配多种体型,使其能够满足用户多样化的试衣需求。
框架设计
近些年,虽然模型仍层出不穷,但模型设计逐渐走向同质化。主要可以分为3个部分:
(1)输入信号(图像 / 视频 / 文本 /timestep)转化为 embedding 参入到后续网络计算中;
(2)基础计算单元:以 Convolution Block 和 Transformer Block 构成;
(3)信息交互单元则根据 embedding 之间的不同,可以通过 spatially-aligned operation 和 non-spatially aligned operation 的多种方式实现融合。
在框架设计上,研究团队遵循简洁有效的原则,按以上的基础思路,首先确定了需要何种输入信号,并根据信号的差异化采用不同的特征交互方式。
在试衣场景中,需要3个控制信号:
- 模特控制:模型提取模特 id,姿态等控制信号,实现模特的控制。
- 服饰控制:服饰的平铺图、服饰的上身图、饰品(帽子、包、鞋子等)。
- 图像全局控制:文本描述。
Outfit Anyone采用了以下的控制信号植入形式:
- 模特控制:利用 spatially aligned operation ,本身作为模特图抽取特征内容,与目标图像在空间对齐。
- 服饰控制:本身与模特图空间不能对齐,需要进行形变操作,再通过非线性的操作进行特征融合。
- 背景、质量等控制:利用 attention 机制实现语义层次特征与图像特征的融合。
目前,基于 Diffusion Model 的生成模型强调生成内容在语义层面的对齐性,所以常采用以 CLIP 为代表的图像语义抽取模型进行特征提取,但这对于试衣模型需要保留所输入服饰的纹理细节矛盾。因此,现有基于 CLIP 特征的试衣模型难以准确完整的还原服饰本身的特性,采用对服饰纹理细节可还原 / 生成的网络为佳。
而针对于模特相关的控制信号,在训练时,本身是输入模特图的一种抽象信号,可作为输入模特图的一个特征通道,在同一网络中,通过 Channel 维度进行信息整合,并不需要遵循 ControlNet 的设计,额外增加网络进行处理,从而一定程度简化模型结构。
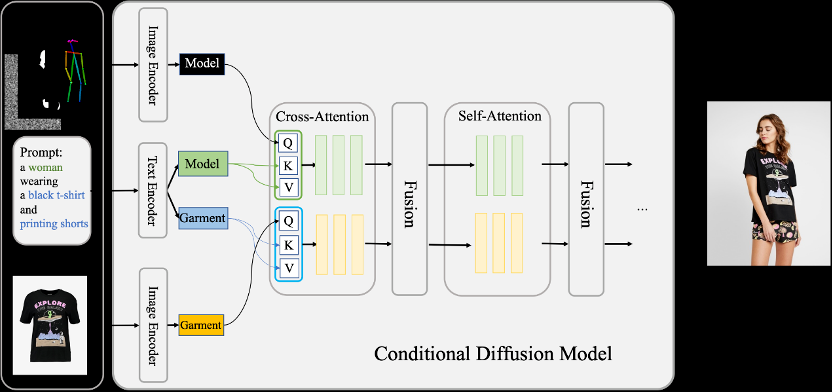
基于以上思考,作者设计了 Outfit Anyone 的模型框架,将多种不同的输入信号,输入进两个网络流中,通过融合的方式实现可控生成。
数据
作者扩充了现有的公开服饰数据集,构建了一个大规模的虚拟试衣服饰数据集。整个数据涵盖了各种类目,包含大量高质量图片。此外,为了实现高质量的服饰还原,作者充分地整理和提取了服饰相关的材质属性等信息。
 微信扫一扫
微信扫一扫